Access and use data

Raw sensor data is collected by edge code. This edge code can either talk to sensor hardware directly or may obtain data from an abstraction layer (not show in image above). Edge code may forward unprocessed sensor data, do light processing to convert raw sensor values into final data products, or may use CPU/GPU-intensive workloads (e.g. AI application) to extract information from data-intensive sensors such as cameras, microphone or LIDAR.
Sensor data from nodes that comes in numerical or textual form (e.g. temperature) is stored natively in our time series database. Sensor data in form of large files (images, audio, movies..) is stored in the Waggle object store, but is referenced in the time series data (thus the dashed arrow in the figure above). Thus, the primary way to find all data (sensor and large files) is via the Waggle sensor query API described below.
Currently the Waggle sensor database contains data such as:
- Relative humidity, barometric pressure, ambient temperature and gas (VOC) BME680.
- Rainfall measurements (Hydreon RG-15).
- AI-based cloud coverage estimation from camera images.
- AI-based object counts from camera images.
- System data such as uptime, cpu and memory.
Data can be accessed in realtime via our data API or in bulk via data bundles.
Data API
Waggle provides a data API for immediate and flexible access to sensor data via search over time and metadata tags. It is primarily intended to support exploratory and near real time use cases.
Due to the wide variety of possible queries, we do not attempt to provide DOIs for results from the data API. Instead, we leave it up to users to organize and curate datasets for their own applications. Long term, curated data is instead provided via data bundles.
There are two recommended approaches to working with the Data API:
- Using the Python Sage Data Client.
- Using the HTTP API.
Each is appropriate for different use cases and integrations, but generally the following rule applies:
If you just want to get data into a Pandas dataframe for analysis and plotting, use the sage-data-client, otherwise use the HTTP API.
Using Sage data client
The Sage data client is a Python library which streamlines querying the data API and getting the results into a Pandas dataframe. For details on installation and usage, please see the Python package.
Using HTTP API
This example shows how to retrieve data the latest data from a specific sensor (you can adjust the start field if you do not get any recent data):
curl -H 'Content-Type: application/json' https://data.sagecontinuum.org/api/v1/query -d '
{
"start": "-10s",
"filter": {
"sensor": "bme680"
}
}
'
Example results:
{"timestamp":"2021-08-09T19:26:03.880781217Z","name":"iio.in_humidityrelative_input","value":70.905,"meta":{"node":"000048b02d15bdcd","plugin":"plugin-metsense:0.1.1","sensor":"bme680"}}
{"timestamp":"2021-08-09T19:26:03.878659392Z","name":"iio.in_pressure_input","value":975.78,"meta":{"node":"000048b02d15bdcd","plugin":"plugin-metsense:0.1.1","sensor":"bme680"}}
{"timestamp":"2021-08-09T19:26:03.872652127Z","name":"iio.in_resistance_input","value":93952,"meta":{"node":"000048b02d15bdcd","plugin":"plugin-metsense:0.1.1","sensor":"bme680"}}
{"timestamp":"2021-08-09T19:26:03.874998057Z","name":"iio.in_temp_input","value":27330,"meta":{"node":"000048b02d15bdcd","plugin":"plugin-metsense:0.1.1","sensor":"bme680"}}
Accessing file uploads
User applications can upload files for AI training purposes. These files stored in an S3 bucket hosted by the Open Storage Network.
To find these files use the filter "name":"upload" and specify additional filters to limit search results, for example:
curl -s -H 'Content-Type: application/json' https://data.sagecontinuum.org/api/v1/query -d '{
"start": "2021-09-10T12:51:36.246454082Z",
"end":"2021-09-10T13:51:36.246454082Z",
"filter": {
"name":"upload",
"plugin":"imagesampler-left:0.2.3"
}
}'
Output:
{"timestamp":"2021-09-10T13:19:27.237651354Z","name":"upload","value":"https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d05a0a4/1631279967237651354-2021-09-10T13:19:26+0000.jpg","meta":{"job":"sage","node":"000048b02d05a0a4","plugin":"imagesampler-left:0.2.3","task":"imagesampler-left:0.2.3"}}
{"timestamp":"2021-09-10T13:50:32.29028603Z","name":"upload","value":"https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bc3d/1631281832290286030-2021-09-10T13:50:32+0000.jpg","meta":{"job":"sage","node":"000048b02d15bc3d","plugin":"imagesampler-left:0.2.3","task":"imagesampler-left:0.2.3"}}
{"timestamp":"2021-09-10T12:52:59.782262376Z","name":"upload","value":"https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bdc2/1631278379782262376-2021-09-10T12:52:59+0000.jpg","meta":{"job":"sage","node":"000048b02d15bdc2","plugin":"imagesampler-left:0.2.3","task":"imagesampler-left:0.2.3"}}
{"timestamp":"2021-09-10T13:49:49.084350086Z","name":"upload","value":"https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bdd2/1631281789084350086-2021-09-10T13:49:48+0000.jpg","meta":{"job":"sage","node":"000048b02d15bdd2","plugin":"imagesampler-left:0.2.3","task":"imagesampler-left:0.2.3"}}
For a quick way to only extract the urls from the json objects above, a tool like jq can be used:
curl -s -H 'Content-Type: application/json' https://data.sagecontinuum.org/api/v1/query -d '{
"start": "2021-09-10T12:51:36.246454082Z",
"end":"2021-09-10T13:51:36.246454082Z",
"filter": {
"name":"upload",
"plugin":"imagesampler-left:0.2.3"
}
}' | jq -r .value > urls.txt
The resulting file urls.txt will look like this:
https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d05a0a4/1631279967237651354-2021-09-10T13:19:26+0000.jpg
https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bc3d/1631281832290286030-2021-09-10T13:50:32+0000.jpg
https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bdc2/1631278379782262376-2021-09-10T12:52:59+0000.jpg
https://storage.sagecontinuum.org/api/v1/data/sage/sage-imagesampler-left-0.2.3/000048b02d15bdd2/1631281789084350086-2021-09-10T13:49:48+0000.jpg
To download the files:
wget -i urls.txt
If many files are downloaded, it is better to preserve the directory tree structure to prevent filename collision:
wget -r -i urls.txt
Protected data
While most Waggle data is open and public - some types of data, such as raw images and audio from sensitive locations, may require additional steps:
- You will need a Sage account.
- You will need to sign our Data Use Agreement for access.
- You will need to provide authentication to tools you are using to download files. (ex. wget, curl)
Attempting to download protected files without meeting these criteria will yield a 401 Unauthorized response.
If you've identified protected data you are interested in, please contact us so we can help get you access.
In the case of protected files, you'll need to provide authentication to your tool of choice. These will be your portal username and access token which can be found in the Access Credentials section of the site.
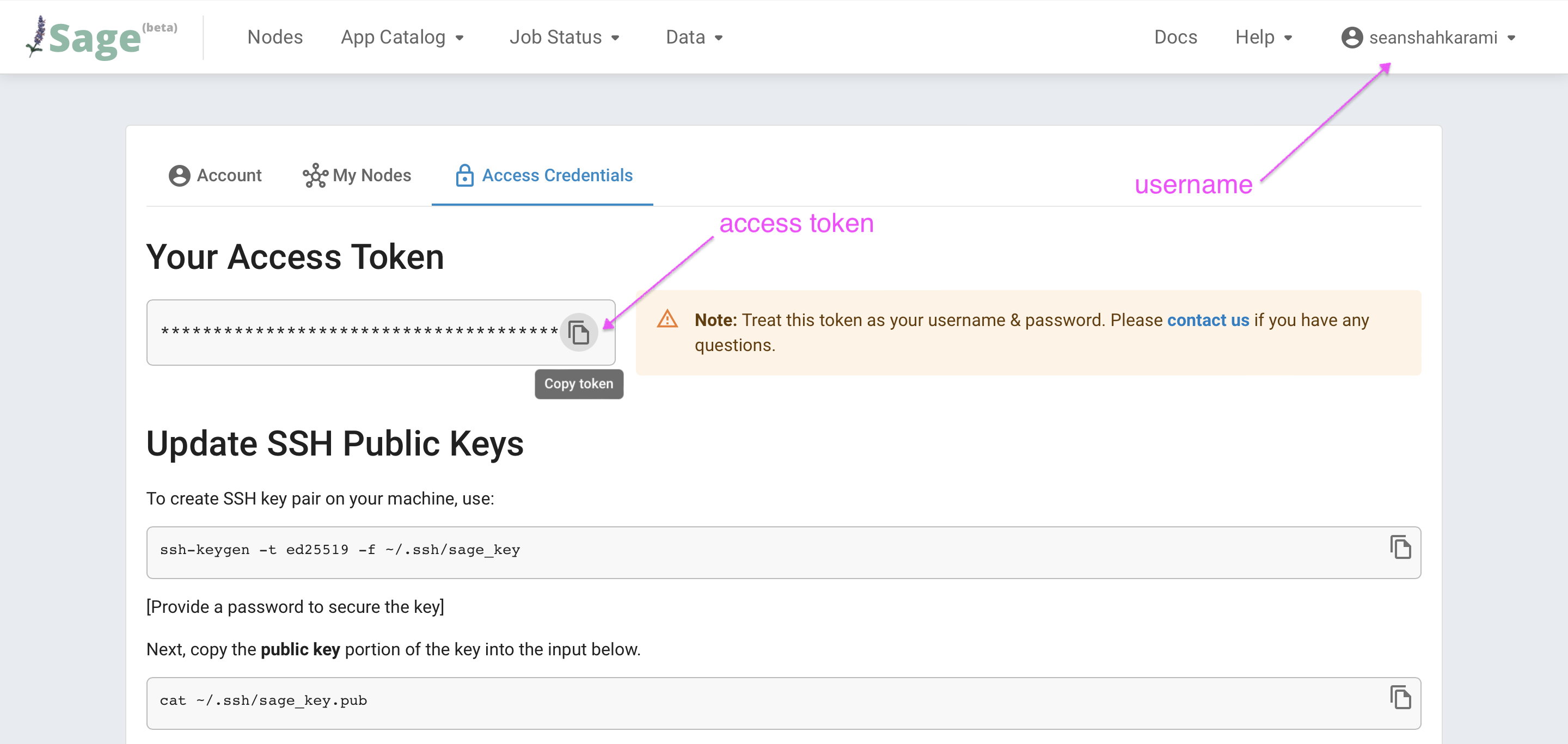
These can be provided to tools like wget and curl as follows:
# example using wget
wget --user=<portal-username> --password=<portal-access-token> -r -i urls.txt
# example using curl
curl -u <portal-username>:<portal-access-token> url